文字エンコーディング(文字エンコード)
文字エンコーディングとは
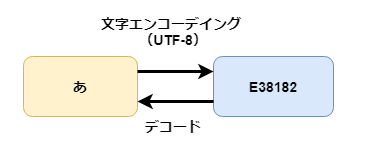
文字をコード化することです。 文字エンコードともいいます。 エンコーデイング(encoding)には 「コード化、符号化」という意味があります。 そしてコード化されたものが「文字コード」になります。例えば「あ」という文字を文字エンコーデイング(UTF-8)すると、 文字コード「E38182」になります(下図参照)。
先ほど「文字エンコーデイング(UTF-8)」と記述しましたが、 UTF-8とは文字エンコーディングの種類の1つです。 文字エンコーディングの種類は多数存在し、 メジャーな文字エンコーディングとしては 「UTF-8」「EUC」「Shift-JIS」などがあります。
それぞれの文字エンコーデイングで文字に対応する文字コードが異なります。 例えば「あ」という文字の場合、文字エンコーデイングと文字コードの対応表は 次のようになります。| 文字エンコーディング | 文字コード |
|---|---|
| UTF-8 | E38182 |
| EUC | A4A2 |
| ShiftJIS | 82A0 |
文字と文字コードの対応表
「UTF-8」「EUC」「Shift-JIS」などの文字エンコーディングには、 それぞれ文字と文字コードの対応表があります。
UTF-8
| 文字 | 文字コード |
|---|---|
| あ | E38182 |
| い | ... |
| う | ... |
EUC
| 文字 | 文字コード |
|---|---|
| あ | A4A2 |
| い | ... |
| う | ... |
Shift-JIS
| 文字 | 文字コード |
|---|---|
| あ | 82A0 |
| い | ... |
| う | ... |
文字エンコーディングという言葉は、 結構あいまいに使われていて、 上記のような文字と文字コードの対応表(対応関係)を 文字エンコーディングという場合もあります。
文字化け
文字化けが起きる理由は次の通りです。
例えば「あ」という文字を文字エンコーディング「UTF-8」で文字コード化すると
「E38182」になります。この「E38182」をデータとしてファイルに保存します。
次にファイルを読み込むんだときには「E38182」というデータが取得できます。 「E38182」というデータを文字エンコーディング「UTF-8」ではなく、 「Shift-JIS」として読み込んだ場合、Shift-JISの対応表に対応した文字が表示されます。 その結果表示されるのは「あ」とは全然違う文字「縺」です。 これが文字化けの起きる理由です。